In-Memory – память и не только

Поиск эффективных способов представления и обработки информации всегда был одной из основных задач информатики. Подход In-Memory, о котором я кратко расскажу в этой статье, как раз является одним из таких способов, и в последнее десятилетие в связи с развитием технологий он получил широкое применение.
Введение
Термин In-Memory используется для обозначения подходов к обработке больших объемов данных в оперативной памяти компьютера. Современные серверы имеют уже с десяток процессоров, каждый из которых – с десяток вычислительных ядер. Объем адресуемой оперативной памяти может быть очень большим (до десятка терабайт). Память также стала дешевле за последние десятилетия, ее производительность выросла. Появилась энергонезависимая память. Производительность даже современных SSD-накопителей значительно уступает производительности оперативной памяти. Поэтому все более привлекательной становилась идея хранить весь набор данных в оперативной памяти и обрабатывать его «на лету» по запросу пользователя, без обращений к внешней системе хранения. И с начала 2000-х годов разработчики стали создавать новые архитектуры СУБД, оптимизированные именно под хранение и обработку данных в памяти, что позволяет существенно увеличить производительность. Традиционные же СУБД оптимизированы на работу с внешней памятью – они стараются минимизировать ввод-вывод, оптимальным образом считывают только нужные блоки данных, используют различные сложные индексы, чтобы быстрее найти нужные блоки с данными и т.д. Также In-Memory применяется не только в СУБД, но и в других аналитических инструментах.
Важными элементами In-Memory, позволяющими обеспечить высокую эффективность, являются поколоночное хранение данных и использование сжатия. Многие реализации In-Memory используют эти механизмы (Oracle Database In-Memory, IBM DB2 BLU, SAP HANA, MS SQL Server xVelocity).
Поколоночное хранение
На схеме ниже представлены построчный и поколоночный способы хранения данных. При традиционном построчном хранении данных все атрибуты каждой записи хранятся друг за другом, т.е. сначала хранятся все атрибуты первой записи, затем второй и т.д. При приборке данных по условию, накладываемому на атрибуты, происходит считывание записей целиком (всех атрибутов). Это приводит к избыточному вводу-выводу. Такой подход обеспечивает хорошую производительность операций, работающих со строкой целиком (например, обновление). Но при необходимости доступа только к отдельным атрибутам эффективность выполнения операций снижается из-за накладных расходов, связанных с обработкой всей строки целиком.
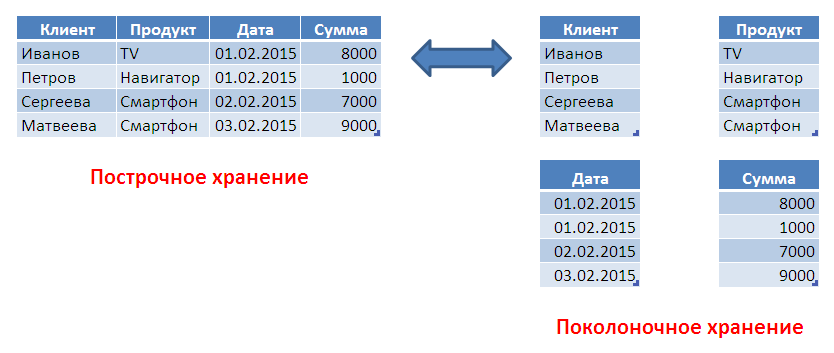
При поколоночном хранении эффективность доступа к отдельным атрибутам заметно повышается. Значения каждого атрибута хранятся в непрерывных участках памяти, а значит, операции сканирования и фильтрации, агрегации, вычисления выражений могут быть выполнены очень эффективно. Поэтому для задач аналитики такой подход выглядит как более подходящий. Но операции, требующие обработки всей строки целиком (вставка, обновление, выборка всех атрибутов), выполняются уже не так эффективно по сравнению с традиционным способом хранения.
Поколоночное хранение может применяться и для представления данных во внешней памяти, в том числе в СУБД, ориентированных на внешнее хранение. Одним из стандартных форматов такого представления являются Parquet-файлы.
Сжатие
За счет того, что данные в одном атрибуте имеют общий тип и часто повторяются, их можно дополнительно сжимать, при этом экономится память, и мы можем обработать больший объем данных. Также в процессе сжатия все значения можно представить целыми числами, с которыми процессор умеет работать быстрее всего.
Для сжатия используются разные схемы, иногда пользователь сам может контролировать этот процесс, в зависимости от типов данных атрибутов, количества уникальных значений, порядка сортировки.
Один из вариантов – упорядочить наши данных по атрибуту «Дата». Представить даты в виде целых чисел и закодировать, указывая разницу между текущим и предыдущим значением (схема ниже). При этом для кодирования маленьких целочисленных смещений можно использовать всего 1 байт на смещение. Когда его станет недостаточно, можно начать кодирование следующей порции заново.

Сжатие не только позволяет экономить память, но и повышает производительность за счет того, что объем данных, который нужно переместить из памяти в кэш процессора при выполнении запроса, сокращается, при этом процессор может выполнять распаковку данных параллельно с пересылкой из памяти очередной порции. Также все современные процессоры могут выполнять операции не над одним значением, а сразу над множеством значений (векторизация), и эта возможность активно используется в In-Memory.
DWARF-сжатие многомерных данных
Поколоночное хранение использует для сжатия только информацию о распределении данных внутри атрибута-столбца. Однако в многомерных данных измерения также коррелируют между собой, и эту информацию также можно использовать для сжатия данных. Алгоритм DWARF как раз выполняет такую процедуру.
DWARF строит дерево, на каждом уровне которого размещаются элементы и их комбинации для конкретного измерения источника. При этом элементы не дублируются, за счет чего достигается сжатие (сжатие т.н. префиксной избыточности). Т.е. если в нашей таблице фактов значение «Иванов» будет встречаться 500 раз, в дереве оно появится только один раз на верхнем уровне. Также алгоритм выделяет агрегаты и описывает, как их можно вычислить через «дочерние» агрегаты нижнего уровня.
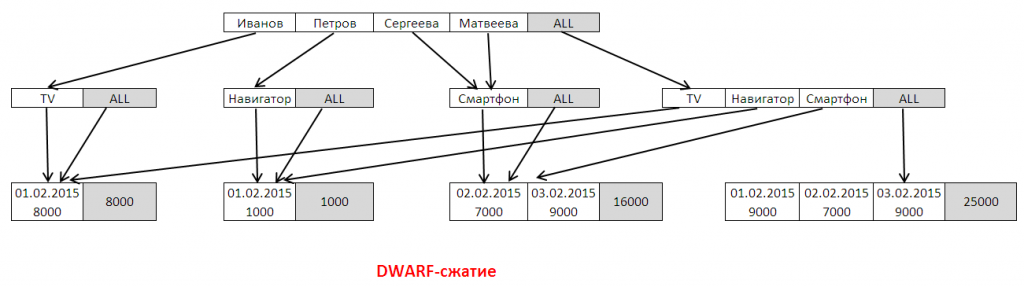
На рисунке ячейки ALL — это ссылки на элементы, образующие данный агрегат (вычисляется один агрегат как сумма). Например, в ячейке TV | ALL , ALL – это агрегат для <Иванов, TV> по всем измерениям, лежащим на уровнях ниже.
Обратите внимание, что элементы «Смартфон» а также элементы с датами переиспользуются – в них идет несколько стрелок. Это сжатие т.н. суффиксной избыточности.
Когда пользователь хочет увидеть данные, алгоритм просматривает дерево и находит путь, соответствующий фильтру пользователя и приводящий к нужным данным. Агрегаты вычисляются рекурсивно по ссылкам ALL.
Алгоритм DWARF при конструировании дерева чувствителен к порядку следования измерений в источнике, и в ряде случаев вместо сжатия его использование может привести к увеличению потребления памяти.
Применение
Подход In-Memory оправдан в ситуациях, когда нужно оперативно обрабатывать большие объемы информации «целиком», особенно когда процесс итерационный по своей сути, т.е. необходимо выполнить несколько итераций вычислений, например, с разными параметрами. Сюда относятся как раз задачи аналитики, задачи вычисления бюджетов и финансового моделирования, планирование производства продукции, различные вычислительные задачи в науке и т.д. В приложениях, связанных с транзакционной обработкой данных (различные учетные системы), этот подход может не дать существенных преимуществ в плане производительности, так как доступ к информации там осуществляется, как правило, избирательно, по ключу, и традиционные СУБД справляются с этим и так хорошо.
Поддержка в СУБД
Вы можете опробовать технологию In-Memory уже сейчас, так как она доступна в современных СУБД.
1. MS SQL Server 2014 Hekaton предоставляет оптимизированный механизм работы с данными в памяти. Для создания таблицы в памяти достаточно использовать CREATE TABLE.. WITH (MEMORY_OPTIMIZED=ON). При создании БД следует указать группу файлов для MEMORY OPTIMIZED DATA, чтобы обеспечить сохранность данных путем записи также на диск на случай сбоев.
2. Oracle Database 12c предоставляет опцию In-memory, которая по умолчанию не активна. Для ее активации нужно выделить память под поколоночное хранение через команду ALTER SYSTEM SET inmemory_size = 20G scope=spfile. Далее можно помещать отдельные таблицы в In-Memory-хранилище по команде ALTER TABLE .. INMEMORY.
3. IBM DB2 10.5 поддерживает In-Memory через расширение BLU Accelerator. Для создания таблицы можно использовать CREATE TABLE.. organize by column.
In-Memory в Prognoz Platform
Некоторые BI-решения также используют технологию In-Memory. Это позволяет повысить производительность, даже если ваши источники данных не поддерживают In-Memory, снизить нагрузку на источники. Также для задач персональной аналитики и аналитики в небольших группах использование In-Memory может избавить от необходимости внедрения традиционных ХД/OLAP-решений. Хотя, конечно, в общем случае In-Memory не может заменить эти технологии, т.к. при создании ХД/OLAP-витрин данные очищаются и интегрируются, ведется аккуратное отслеживание всей истории изменений данных (медленно меняющиеся измерения) и т.д. Сама по себе In-Memory это обеспечить не может, но для задач быстрого прототипирования выполнять интеграцию на лету в In-Memory возможно, и это один из сценариев использования.
Наша Prognoz Platform также использует подход In-Memory для целей повышения производительности доступа к данным. Для каждого многомерного источника, определенного в платформе, можно включить кэш In-Memory. При этом платформа извлечет все данные из систем-источников, выполнит вычисления и агрегацию, если они настроены, построит многомерную структуру данных и сохранит ее в БД. В последующем при первом обращении к источнику многомерная структура считывается в память, и далее все запросы к ней будут выполняться с использованием данного кэша. Кэш разделяется между всеми пользователями.
Возможность In-Memory есть смысл применять для больших и часто используемых источников данных, которые используют нетривиальные запросы для извлечения данных, тогда это даст ощутимый прирост производительности всей BI-системы.Prognoz Platform также может использовать DWARF-сжатие при работе с большими временными рядами. Однако алгоритм использует только префиксное сжатие, так как на практике оно дает наибольший вклад. Этот подход особенно хорошо работает, когда источник данных плотно заполнен, т.е. данные присутствуют почти на всех сочетаниях элементов измерений. В платформе DWARF используется только на тех источниках данных, чья структура подходит для сжатия по алгоритму DWARF.
Технология In-Memory в настоящее время активно применяется в индустрии, а современные инфраструктуры и инфраструктуры будущего смотрят уже в сторону параллельной и распределенной обработки In-Memory, чьи возможности масштабирования просто не сравнимы с возможностями одного сервера.