Одна голова хорошо, а много — лучше. Прогнозирование с использованием ансамблей

В данной статье мы кратко расскажем о методах прогнозной аналитики с использованием ансамблей моделей, в частности, о Random Forest – одном из самых популярных методов прогнозной аналитики.
Идея ансамблей следующая. Если нам сложно построить прогнозную модель, которая обеспечивала бы желаемую точность на разнообразных входных данных, мы можем попробовать построить сразу несколько независимых моделей для нашей задачи, чтобы каждая из них обладала определенной точностью (пусть недостаточно высокой), но за счет определенной «рандомизации» эти модели ошибались бы на разных множествах данных. Тогда мы можем комбинировать результаты данных моделей, чтобы в среднем качество результата повысилось. То есть модели будут «сглаживать» ошибки друг друга. За общий результат такого ансамбля можно взять среднее значение или наиболее часто встречающееся. Строгого обоснования, почему это работает, не будет.
Агрегация
Агрегация или bagging (bootstrap aggregating) – это базовый метод построения ансамблей:
1. Из исходного набора данных строится несколько равномерных случайных выборок такого же размера (например, 50, 100 и т.д.). Причем строки могут выбираться с повторами (а некоторые могут вообще не попасть). Это позволит обеспечить случайные вариации в результатах работы прогнозных моделей.
2. На каждой выборке обучается прогнозная модель.
3. При применении моделей их результаты агрегируются – берется наиболее часто встречающееся значение (голосование) или среднее.
Random Forest
Алгоритм Random Forest является развитием идеи агрегации. Мы можем построить не одно дерево решений, а целый «лес» (forest). И если деревья достаточно различаются, в целом результаты работы модели должны быть лучше. Но помимо построения множества случайных выборок в Random Forest также в каждом узле дерева используется случайная выборка только части атрибутов из общего количества. Это также увеличивает случайность и сокращает время построения ансамбля. Количество деревьев в лесе можно увеличивать до тех пор, пока ошибка модели сокращается (100, 200, 500 деревьев и т.д.).
Алгоритм Random Forest реализован в Prognoz Platform. Он не доступен в интерфейсе пользовательских инструментов, но присутствует в библиотеке методов. Его можно использовать как для предсказания количественных атрибутов, так и для классификации данных по каким-либо категориям. Он прост в использовании, обеспечивает высокую точность, имеет хорошую производительность, за счет чего и приобрел большую популярность.
Пример использования Random Forest в индустрии
Один из примеров применения Random Forest – оценка положения тела человека в пространстве контроллером Microsoft Kinect. Если вы не знакомы с Kinect, можете поискать информацию о нем. Это контроллер для управления игровой консолью Xbox, позволяющий управлять персонажами игр при помощи движений своего тела, а также для голосового управления.
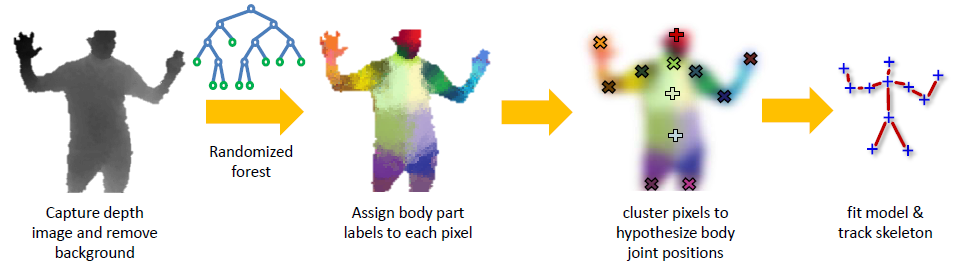
Рисунок 1. Схема работы Kinect (Pushmeet Kohli, Jamine Shotton)
На рисунке представлена схема оценки положения тела. Сначала при помощи сенсоров Kinect строит изображение фигуры с учетом информации о глубине – положении точек ближе/дальше в пространстве относительно сенсоров. Каждый пиксель изображения несет эту информацию в виде пространственных признаков – векторов расстояний от данной точки до определенных точек.
Далее с помощью обученного классификатора Random Forest для каждого пикселя получается вероятность принадлежности к определенной части тела. Чтобы такой классификатор работал точно для каждого пользователя, нужен очень большой набор данных для его «обучения». Сам процесс обучения длительный и занимает на таких наборах данных целые дни и недели процессорного времени. Но уже готовый алгоритм работает очень быстро. В данном случае – в реальном времени.
Заключение
Рост производительности компьютеров и совершенствование алгоритмов позволяют решать задачи прогнозной аналитики все точнее и быстрее. Ансамбли моделей – это как раз одно из активно развивающихся направлений. Практика показала, что они относительно просты в обучении, дают существенный прирост точности, могут хорошо работать как с большими, так и с маленькими объемами данных. Этот метод, несомненно, займет свою нишу.