Оптимизация ETL при работе с реляционными приемниками

Александр Грива
Задачи, решаемые аналитическими системами, могут быть совершенно разными, но неотъемлемой частью любой системы являются данные, на которых производится анализ. «Форсайт. Аналитическая платформа» позволяет работать как с внешними источниками данных (имею в виду подключение к уже существующим источникам), так и с источниками данных, которые хранятся в структурах «Форсайт. Аналитической платформы». В этой статье я расскажу о том, как наиболее оптимально организовать наполнение данных во внутренних структурах платформы и покажу лучший способ выгрузки данных во внешние реляционные источники, используя стандартные объекты платформы.
Основным инструментом по работе с загрузкой и выгрузкой данных в платформе является «Задача ETL»:
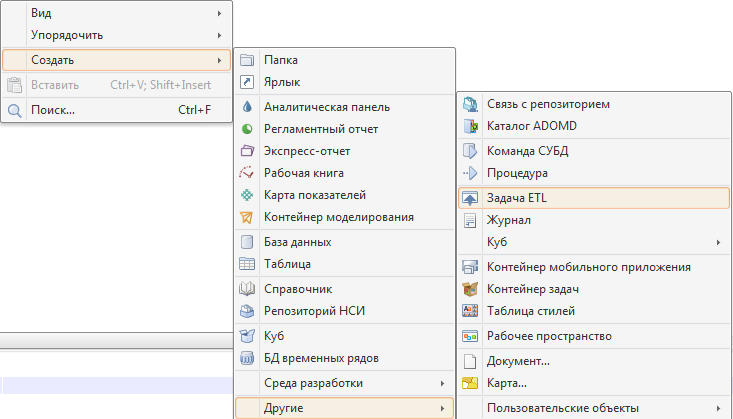 Этот объект имеет широкие возможности. Назову некоторые из них:
Этот объект имеет широкие возможности. Назову некоторые из них:
-
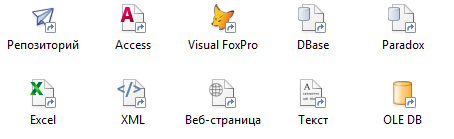
- загрузка данных из различных внешних источников, будь то файлы Excel, Access, текстовые файлы и другие, а также из источников данных, для которых существуют сторонние OLEDB -провайдеры;
-
- преобразование данных за счет ряда стандартных инструментов для их фильтрации, группировки, объединения, разделения и редактирования;

- выгрузка данных соответственно в файлы Excel, Access и другие, а также реляционные структуры хранения данных.
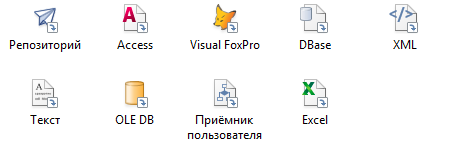 В настоящее время все чаще возникают задачи по анализу данных, которые занимают гигабайты. Они могут поступать из различных источников, и зачастую требуется свести их в один. Рассмотрим, как это лучше сделать. Для начала определимся, каким приемником следует пользоваться и почему. Для загрузки данных в один источник существуют два варианта приемников задачи ETL, которыми можно воспользоваться, а именно, приемник репозитория и приемник OLEDB. Рассмотрим по отдельности плюсы и минусы каждого.
В настоящее время все чаще возникают задачи по анализу данных, которые занимают гигабайты. Они могут поступать из различных источников, и зачастую требуется свести их в один. Рассмотрим, как это лучше сделать. Для начала определимся, каким приемником следует пользоваться и почему. Для загрузки данных в один источник существуют два варианта приемников задачи ETL, которыми можно воспользоваться, а именно, приемник репозитория и приемник OLEDB. Рассмотрим по отдельности плюсы и минусы каждого.
 Неоспоримыми плюсами приемника репозитория является то, что задачи по загрузке данных используют оптимизированные SQL-запросы, что позволяет ускорить выполнение операции в десятки, а иногда и в сотни раз. Именно приемник репозитория также позволяет осуществлять обновление существующих записей в таблицах.
Минусами приемника репозитория является требование наличия в репозитории платформы объекта таблицы или присоединенной таблицы, то есть помимо самой задачи ETL мы должны иметь еще и дополнительные объекты.
Теперь рассмотрим приемник OLEDB и начнем с его плюсов. К ним можно отнести более широкий спектр поддерживаемых СУБД (по сути, это может быть любая СУБД, имеющая адаптированный OLEDB-провайдер). Кроме того, для приемника OLEDB нет необходимости создавать дополнительные объекты репозитория, т.к. все настройки подключения указываются прямо в приемнике задачи ETL.
Но и для приемника OLEDB не обойтись без явных минусов. В частности, строка подключения формируется открыто, а это значит, что логин и пароль для подключения к БД хранятся в явном виде. Поскольку объект OLEDB является универсальным, то к нему нельзя применять специфические для каждой СУБД способы оптимизации процесса загрузки.
Как следствие предыдущего замечания, в приемнике OLEDB не реализовано обновление существующих записей, т.к. не каждый OLEDB-провайдер поддерживает обновление записей.
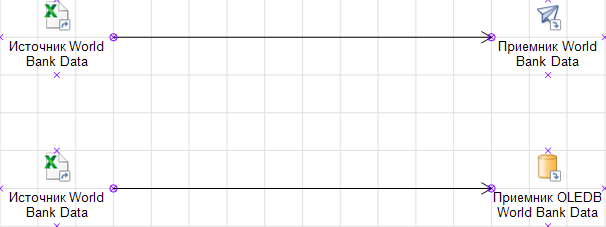
Рассмотрим элементарный пример загрузки данных. Мы имеем небольшой файл с 1000 записей. Обратите внимание на разницу в скорости выполнения задачи. Вся операция по вычитыванию и загрузке данных в приемник репозитория заняла меньше секунды.
Неоспоримыми плюсами приемника репозитория является то, что задачи по загрузке данных используют оптимизированные SQL-запросы, что позволяет ускорить выполнение операции в десятки, а иногда и в сотни раз. Именно приемник репозитория также позволяет осуществлять обновление существующих записей в таблицах.
Минусами приемника репозитория является требование наличия в репозитории платформы объекта таблицы или присоединенной таблицы, то есть помимо самой задачи ETL мы должны иметь еще и дополнительные объекты.
Теперь рассмотрим приемник OLEDB и начнем с его плюсов. К ним можно отнести более широкий спектр поддерживаемых СУБД (по сути, это может быть любая СУБД, имеющая адаптированный OLEDB-провайдер). Кроме того, для приемника OLEDB нет необходимости создавать дополнительные объекты репозитория, т.к. все настройки подключения указываются прямо в приемнике задачи ETL.
Но и для приемника OLEDB не обойтись без явных минусов. В частности, строка подключения формируется открыто, а это значит, что логин и пароль для подключения к БД хранятся в явном виде. Поскольку объект OLEDB является универсальным, то к нему нельзя применять специфические для каждой СУБД способы оптимизации процесса загрузки.
Как следствие предыдущего замечания, в приемнике OLEDB не реализовано обновление существующих записей, т.к. не каждый OLEDB-провайдер поддерживает обновление записей.
Рассмотрим элементарный пример загрузки данных. Мы имеем небольшой файл с 1000 записей. Обратите внимание на разницу в скорости выполнения задачи. Вся операция по вычитыванию и загрузке данных в приемник репозитория заняла меньше секунды.
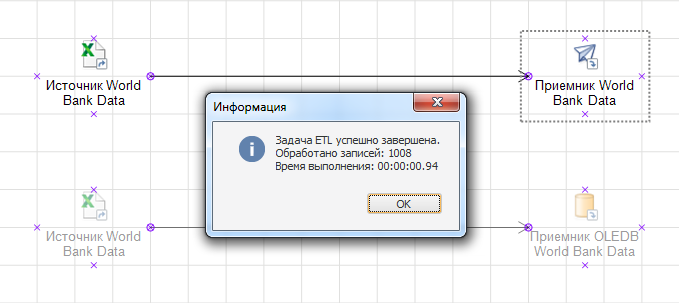 В то время как задача с использованием приемника OLEDB заняла порядка полутора секунд.
В то время как задача с использованием приемника OLEDB заняла порядка полутора секунд.
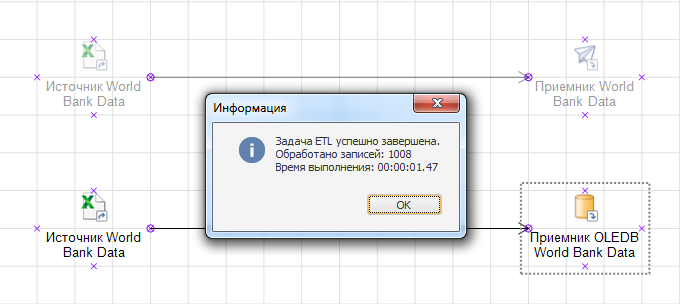 Таким образом, всего на 1000 записей получаем разницу в полсекунды. На первый взгляд, это незначительная разница, но представим, как она возрастет с увеличением объемов данных в тысячи раз.
В данном примере был рассмотрен вариант с загрузкой данных в пустую таблицу. Теперь обратите внимание на ситуацию, когда таблица не пустая и стоит задача не перезаписать данные, а дополнить и обновить их.
Таким образом, всего на 1000 записей получаем разницу в полсекунды. На первый взгляд, это незначительная разница, но представим, как она возрастет с увеличением объемов данных в тысячи раз.
В данном примере был рассмотрен вариант с загрузкой данных в пустую таблицу. Теперь обратите внимание на ситуацию, когда таблица не пустая и стоит задача не перезаписать данные, а дополнить и обновить их.
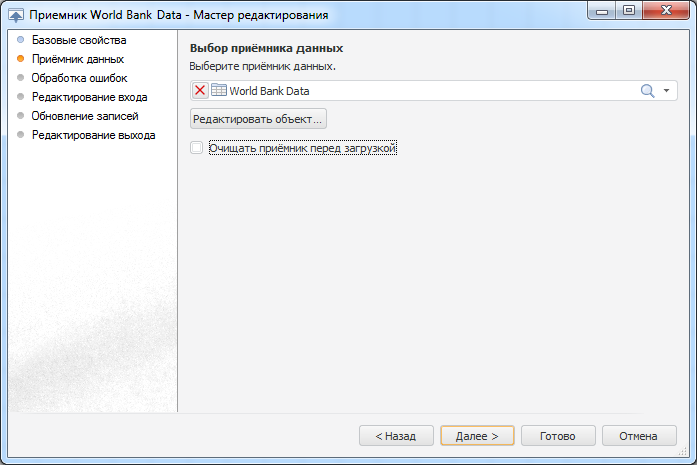 Решить данную задачу позволяет именно приемник репозитория. Открыв его на редактирование и перейдя на страницу «Приёмник данных», нужно снять флаг «Очищать приёмник перед загрузкой». Страницу «Обработка ошибок» пока оставим без изменений и дойдем до страницы обновление записей. Здесь нужно отмечать поля, по которым обеспечивается уникальность записей (первичные или уникальные ключи таблицы).
Решить данную задачу позволяет именно приемник репозитория. Открыв его на редактирование и перейдя на страницу «Приёмник данных», нужно снять флаг «Очищать приёмник перед загрузкой». Страницу «Обработка ошибок» пока оставим без изменений и дойдем до страницы обновление записей. Здесь нужно отмечать поля, по которым обеспечивается уникальность записей (первичные или уникальные ключи таблицы).
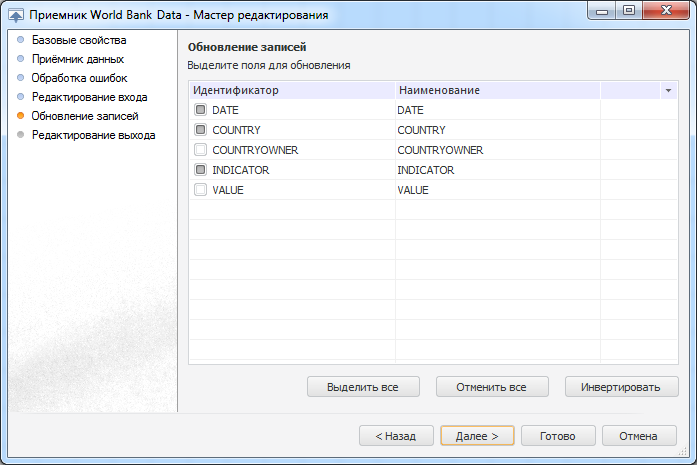 Таким образом, при выполнении загрузки данных произойдут добавление новых записей и обновление полей COUNTRYOWNER и VALUE для существующих записей.
Далее предлагаю рассмотреть еще некоторые особенности настройки приемников в задаче ETL, которые связаны с наличием некорректных данных в источниках, к примеру, когда посреди столбца с целочисленными значениями случайно попадается строка. Для обработки данной ситуации в приемниках задачи ETL предусмотрена настройка на странице «Обработка ошибок». Покажу ее на примере приемника репозитория.
Таким образом, при выполнении загрузки данных произойдут добавление новых записей и обновление полей COUNTRYOWNER и VALUE для существующих записей.
Далее предлагаю рассмотреть еще некоторые особенности настройки приемников в задаче ETL, которые связаны с наличием некорректных данных в источниках, к примеру, когда посреди столбца с целочисленными значениями случайно попадается строка. Для обработки данной ситуации в приемниках задачи ETL предусмотрена настройка на странице «Обработка ошибок». Покажу ее на примере приемника репозитория.
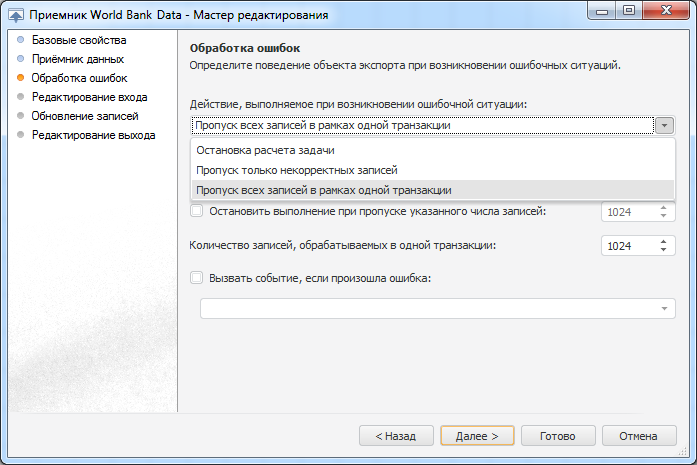 Итак, вспомним нашу ситуацию, когда в файле источника вместо числа встретилась строка. Для исправления этой ситуации нам доступны три варианта обработки ошибок: остановка расчета, пропуск только некорректных записей, пропуск всех записей в рамках одной транзакции. Кратко охарактеризую каждый вариант:
Остановка расчета: чаще всего используется при загрузке критически важных данных. В данном случае при возникновении ошибки выполнение задачи прервется:
Итак, вспомним нашу ситуацию, когда в файле источника вместо числа встретилась строка. Для исправления этой ситуации нам доступны три варианта обработки ошибок: остановка расчета, пропуск только некорректных записей, пропуск всех записей в рамках одной транзакции. Кратко охарактеризую каждый вариант:
Остановка расчета: чаще всего используется при загрузке критически важных данных. В данном случае при возникновении ошибки выполнение задачи прервется:
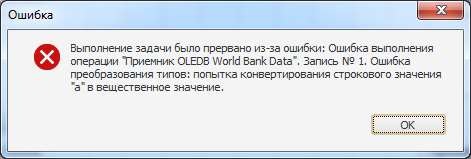 Пропуск только некорректных записей: вставка начинает выполняться по одной записи, и в случае появления ошибки пропускается лишь эта запись. Данный способ обработки ошибок чаще всего используется при необходимости загрузки максимального количества данных.
Пропуск только некорректных записей: вставка начинает выполняться по одной записи, и в случае появления ошибки пропускается лишь эта запись. Данный способ обработки ошибок чаще всего используется при необходимости загрузки максимального количества данных.
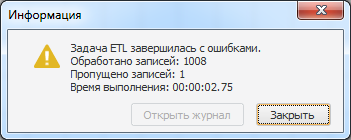 Стоит отметить, что при использовании приемника репозитория и варианта «Пропуск только некорректных записей» время выполнения задачи будет соизмеримо с ее выполнением через приемник OLEDB, т.к. в таком случае отключается возможность использования быстрой вставки.
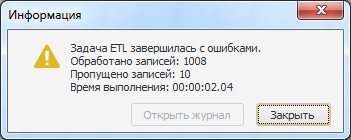
Пропуск всех записей в рамках одной транзакции: при возникновении ошибки все записи, идущие в рамках этой транзакции, будут пропущены. Количеством записей в транзакции можно управлять также на странице «Обработка ошибок» параметром «Количество записей, обрабатываемых в одной транзакции». Для примера установим количество записей в транзакции равное 10 и выполним задачу. В результате выполнения получим информацию о 10 пропущенных записях.
Стоит отметить, что при использовании приемника репозитория и варианта «Пропуск только некорректных записей» время выполнения задачи будет соизмеримо с ее выполнением через приемник OLEDB, т.к. в таком случае отключается возможность использования быстрой вставки.
Пропуск всех записей в рамках одной транзакции: при возникновении ошибки все записи, идущие в рамках этой транзакции, будут пропущены. Количеством записей в транзакции можно управлять также на странице «Обработка ошибок» параметром «Количество записей, обрабатываемых в одной транзакции». Для примера установим количество записей в транзакции равное 10 и выполним задачу. В результате выполнения получим информацию о 10 пропущенных записях.
 Еще один полезный способ оптимизации задачи ETL – пакетная обработка данных. В силу клиентской модели работы задачи ETL, при ее выполнении все данные из источников цепочки сначала вычитываются в память процесса, а затем передаются дальше по цепочке выполнения. В случаях, когда объемы данных измеряются гигабайтами, этот вариант может привести к чрезмерному потреблению памяти на компьютере, где выполняется задача ETL. Но есть решение и для данной проблемы – в задаче ETL предусмотрен вариант пакетной обработки данных. Он позволяет вычитывать данные из источника небольшими пакетами и передавать по цепочке выполнения небольшие порции данных.
Использование этой настройки позволяет обрабатывать в задаче ETL большие данные даже на слабых компьютерах и в рамках x86 процессов с ограниченным объемом оперативной памяти. Для активации настройки необходимо в главном меню задачи ETL выбрать пункт «Задача» и в раскрывшемся меню выбрать «Свойства». Настройка располагается на странице «Параметры задачи».
Еще один полезный способ оптимизации задачи ETL – пакетная обработка данных. В силу клиентской модели работы задачи ETL, при ее выполнении все данные из источников цепочки сначала вычитываются в память процесса, а затем передаются дальше по цепочке выполнения. В случаях, когда объемы данных измеряются гигабайтами, этот вариант может привести к чрезмерному потреблению памяти на компьютере, где выполняется задача ETL. Но есть решение и для данной проблемы – в задаче ETL предусмотрен вариант пакетной обработки данных. Он позволяет вычитывать данные из источника небольшими пакетами и передавать по цепочке выполнения небольшие порции данных.
Использование этой настройки позволяет обрабатывать в задаче ETL большие данные даже на слабых компьютерах и в рамках x86 процессов с ограниченным объемом оперативной памяти. Для активации настройки необходимо в главном меню задачи ETL выбрать пункт «Задача» и в раскрывшемся меню выбрать «Свойства». Настройка располагается на странице «Параметры задачи».
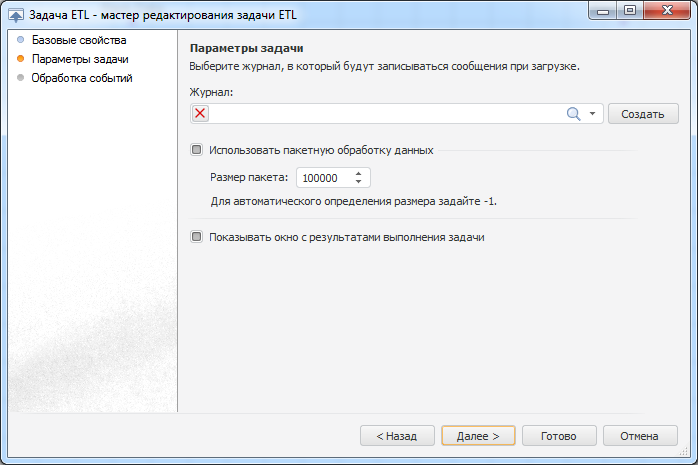 За количество записей в рамках одного пакета отвечает параметр «Размер пакета». Можно оставить значение «-1», и тогда платформа автоматически подберет размер пакета. Если же, по вашему мнению, стоит увеличить или уменьшить размер пакета, то вы можете задать свое значение. Стоит учесть, что использование пакетной обработки данных может привести к увеличению времени выполнения задачи ETL, к примеру, в случаях с использованием обновления данных в приемнике репозитория, поэтому включать ее стоит только тогда, когда пакетная обработка действительно нужна. Использование пакетной обработки также не учитывается, если в цепочке выполнения присутствуют преобразователи «Сортировка» и «Группировка», т.к. для их работы требуется иметь полный набор данных.
В текущей статье мы рассмотрели варианты выбора приемника для загрузки данных и способы обработки ошибок. Назвать единственный верный вариант приемника и его настроек на все случаи невозможно, но надеюсь, что данный материал поможет вам определиться с оптимальным способом загрузки данных в каждом конкретном случае.
За количество записей в рамках одного пакета отвечает параметр «Размер пакета». Можно оставить значение «-1», и тогда платформа автоматически подберет размер пакета. Если же, по вашему мнению, стоит увеличить или уменьшить размер пакета, то вы можете задать свое значение. Стоит учесть, что использование пакетной обработки данных может привести к увеличению времени выполнения задачи ETL, к примеру, в случаях с использованием обновления данных в приемнике репозитория, поэтому включать ее стоит только тогда, когда пакетная обработка действительно нужна. Использование пакетной обработки также не учитывается, если в цепочке выполнения присутствуют преобразователи «Сортировка» и «Группировка», т.к. для их работы требуется иметь полный набор данных.
В текущей статье мы рассмотрели варианты выбора приемника для загрузки данных и способы обработки ошибок. Назвать единственный верный вариант приемника и его настроек на все случаи невозможно, но надеюсь, что данный материал поможет вам определиться с оптимальным способом загрузки данных в каждом конкретном случае. Читайте также
Визуализация данных
«Форсайт. Умные таблицы». А почему же они умные?
Блог Форсайт
Аналитические панели
Отчетность в Платформе «Форсайт»: вчера, сегодня, завтра
Блог Форсайт
Опыт
Лучшие практики зарубежных EPM-решений – теперь в новой версии продукта «Форсайт. Бюджетирование и консолидация»
Блог Форсайт
Мобильные приложения