От прогнозирования временных рядов к искусственному интеллекту

Кто владеет информацией, тот владеет миром.
Натан Ротшильд, основатель английской ветви Ротшильдов
В последнее время вычислительные мощности компаний растут экспоненциально, компании научились аккумулировать информацию не только о своих внутренних процессах, но и собирать внешние данные для получения новых инсайтов для своего бизнеса.
Не многие знают, но платформа Prognoz Platform также позволяет решать широкий класс задач по моделированию и прогнозированию. Но обо всем по порядку.
Корпоративная база данных любого современного предприятия обычно содержит набор данных, хранящих записи о тех или иных фактах либо объектах (например, о товарах, их продажах, клиентах, счетах).
Примерами подобной информации являются сведения о том, как зависят продажи определенного товара от дня недели, времени суток или времени года, какие категории покупателей чаще всего приобретают тот или иной товар, какая часть покупателей одного конкретного товара приобретает другой конкретный товар, какая категория клиентов чаще всего вовремя не отдает предоставленный кредит и т.д.
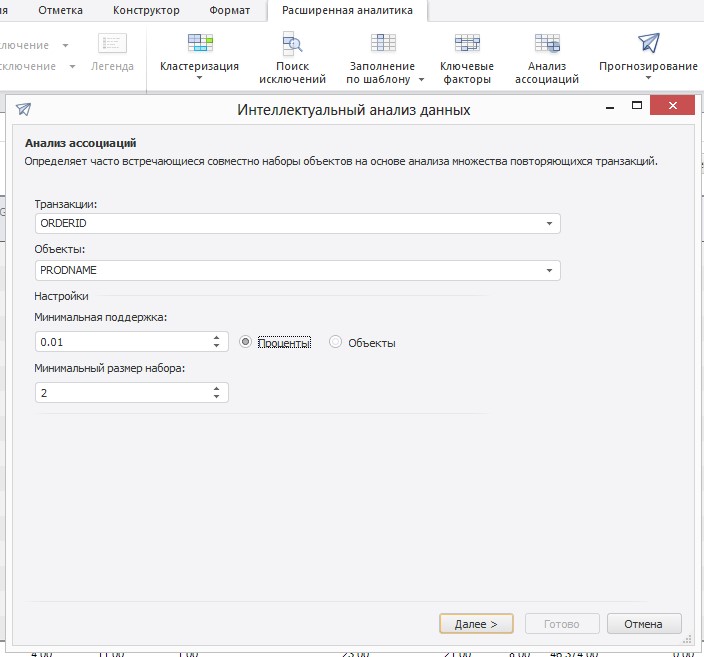
Ассоциация имеет место в том случае, если несколько событий связаны друг с другом. Например, исследование, проведенное в супермаркете, может показать, что 70% купивших творог берут также и сметану, а при наличии скидки от одного производителя такую пару продуктов покупают в 80% случаев. Располагая сведениями о подобной ассоциации, менеджерам легко оценить, насколько действенна предоставляемая скидка.
Для решения такого типа задач с помощью Prognoz Platform вам потребуется подготовить реляционную таблицу, где одним из параметров будет ID товарного чека, вторым параметром категория товара или конкретный товар. Далее необходимо перейти во вкладку «Расширенная аналитика», выбрать метод «Анализ ассоциаций», в визуальном мастере указать «Транзакции» (это колонка ID чека), «Объекты» (это список товаров в чеке или категорий товаров), нажать кнопку «Далее» и получить список наиболее часто встречаемых пар/групп товаров в товарном чеке.
Если набор данных достаточно большой, то для уменьшения размерности задачи вы можете использовать сэмплирование (от англ. Sample – выборка), это вам позволит быстрее получить первый результат.
Если существует цепочка связанных во времени событий, то говорят о последовательности. Так, например, после покупки квартиры в 45% случаев в течение месяца приобретается и новая кухонная плита, а в пределах двух недель 60% новоселов обзаводятся холодильником.
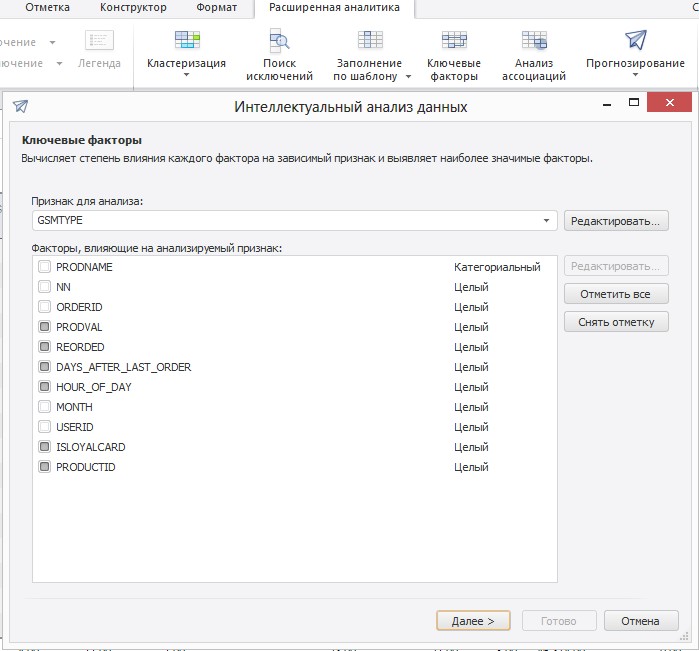
Для решения такого класса задач в Prognoz Platform вы можете применять, например, метод «Ключевые факторы», который позволит выявить такую неявную связь. Вызвав визуальный мастер, достаточно указать столбец, который содержит один из анализируемых признаков по отношению, к которому такая связь должны найтись и отметить столбцы, для которых необходимо проверить такую последовательность.
С помощью классификации выявляются признаки, характеризующие группу, к которой принадлежит тот или иной объект. Это делается посредством анализа уже классифицированных объектов и формулирования некоторого набора правил. Например, может определяться надежность клиента банка по ряду критериев, или выявляться абоненты, склонные к оттоку или покупке какого-то товара.
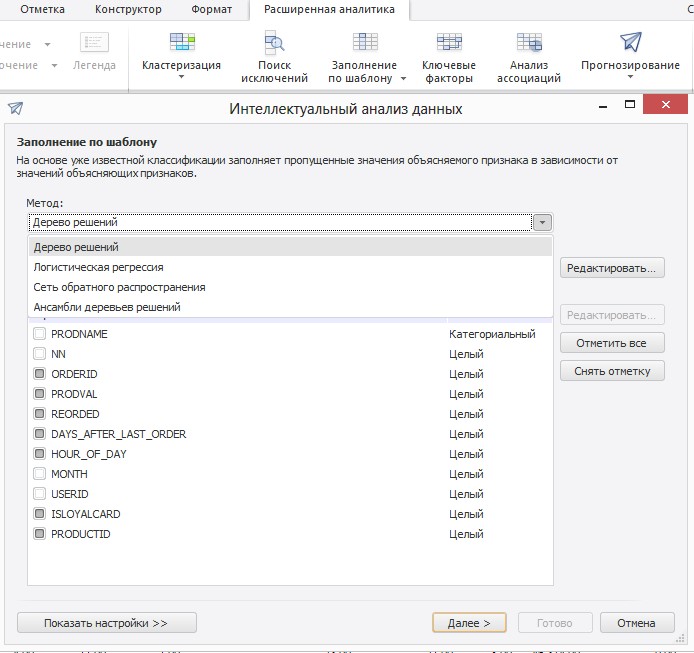
В Prognoz Platform во вкладке «Заполнение по шаблону» вы можете применить логистическую регрессию, которая очень популярна в банковском скоринге, применить методы «Деревья решений» (Decision Tree), «Ансамбль деревьев решений» (Random Forest) или воспользоваться нейронной сетью. В мастере вы указываете признак, для которого строите модель, и отмечаете столбцы, которые будут участвовать в построении модели.
Для уменьшения размерности задачи вы можете для начала воспользоваться методом «Ключевые факторы», который укажет какие признаки наиболее значимы для анализируемого показателя.
Кластеризация отличается от классификации тем, что сами группы заранее не заданы. С помощью кластеризации средства Data Mining самостоятельно выделяют различные однородные группы данных. Как правило, на основе кластеризации формируются новые продукты. Для чего сегментируется целевая аудитория, описывается и на основе этого инсайта формируется лучшее следующее предложение (Next Best Offer).
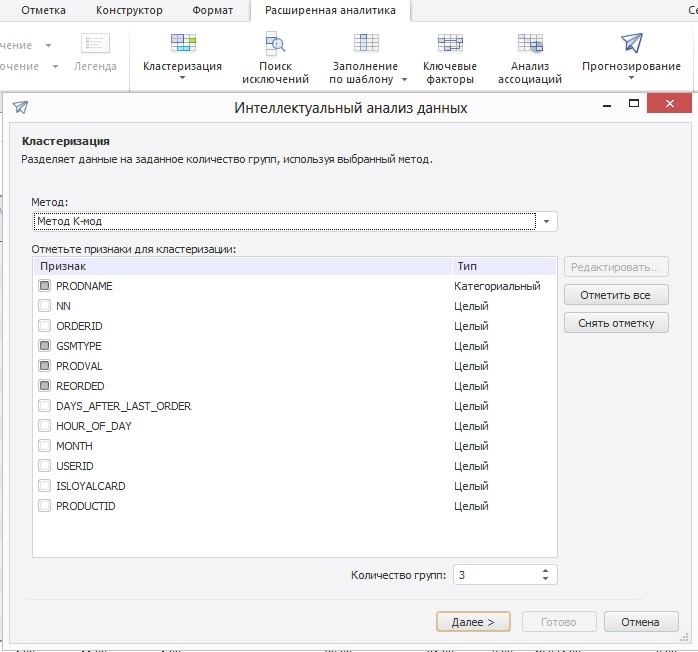
В Prognoz Platform во вкладке «Кластеризация» вы найдете необходимые для расчётов алгоритмы – «Метод К-мод» и «Самоорганизующиеся карты Кохоннена», для проведения кластеризации вам необходимо выбрать количество кластеров и отметить все признаки, по которым будет проведен кластерный анализ.
Основой для всевозможных систем прогнозирования служит историческая информация, хранящаяся в БД в виде временных рядов. Если удается построить шаблоны, адекватно отражающие динамику поведения целевых показателей, есть вероятность, что с их помощью можно предсказать и поведение системы в будущем.
В Prognoz Platform существует целый модуль «Прогнозирование временных рядов» и реализовано огромное число алгоритмов, которые позволяют строить прогнозные модели для временных рядов. Не буду перечислять их все, но без ложной скромности могу сказать, что на сегодняшний день по количеству методов прогнозирования временных рядов платформа является безусловным лидером на рынке, с хорошим запасом опережая даже признанных западных вендоров по этому классу алгоритмов.
Все перечисленные методы реализованы в платформе, однако это не все, что вы можете найти в платформе. Для наиболее продвинутых специалистов data science в платформе реализованы коннекторы к скриптовым языкам R и Python, где реализовано огромное множество методов и алгоритмов от самых простых до многослойных нейронных сетей и даже больше, что дает вам возможность решать на платформе более широкий класс задач: это и автоматизация контроля работы вашего колл-центра, и возможность создания робота самообслуживания, возможность узнать своего клиента при повторном появлении в точке продаж и много чего еще.
О том, как решать те или иные задачи, а также какие методы использовать для их решения, вы узнаете на страницах нашего блога. Удачи вам и умных решений!