BI-поиск в «Форсайт. Аналитической платформе»

Ирина Башкова, Александра Корекова
«Загугли!» – все чаще говорим мы друг другу. Поиск необходимой информации среди огромного объема имеющейся стал неотъемлемой частью не только нашей повседневной жизни, но и работы, особенно если речь идет о больших данных. Давайте разберемся, что значит «загугли» применительно к BI и как это представлено в продукте «Форсайт. Аналитическая платформа».
BI-поиск – друг человека
В широком смысле BI-поиск представляет собой многофункциональную технологию, включающую индексацию, доступ и извлечение как структурированных, так и неструктурированных данных с необходимой метаинформацией, а также способы визуализации результата поиска.
Как и для любого вида поиска, целью BI-поиска является нахождение документов, сведений о них, данных и метаданных, релевантных запросу пользователя.
Хороший BI-поиск действительно выполняет функцию настоящего друга – он понимает пользователя и помогает найти необходимую информацию за минимальное время. BI-поиск знает, что вам нужно, и готов предложить наилучшие варианты, соответствующие вашему запросу.
Без этого поиск не понять…
Для того чтобы реализовать одну из важнейших функций BI-поиска, а именно возвращение наиболее релевантных запросу пользователя результатов, необходимо воспользоваться платформой полнотекстового поиска. Мы выбрали для этих целей платформу Apache Solr.
Solr – это платформа полнотекстового поиска с открытым исходным кодом, написанная на Java. Основой для этой платформы является библиотека Apache Lucene. В общих словах, к основным возможностями Solr можно отнести:
- непосредственно полнотекстовый поиск;
- использование синонимов при поиске;
- управление релевантностью поиска;
- подсветка результатов;
- фасетный поиск (немного об этом здесь https://wiki.apache.org/solr/SolrFacetingOverview);
- извлечение контента документов (например, Word, PDF и т.д.).
Solr, как отдельное веб-приложение, запускается внутри какого-либо сервера, например, Apache Tomcat или Jetty.
Больше узнать о Solr можно тут - http://lucene.apache.org/solr/ и тут https://wiki.apache.org/solr/.
BI-поиск в «Форсайт. Аналитической платформе»
В платформе BI-поиск представляет собой полнотекстовый поиск по содержимому и наименованию источников данных (стандартных кубов и БДВР). В механизм поиска также включена и индексация этих источников на основе их измерений и наличия данных.
Реализован BI-поиск в инструментах экспресс-анализа (OLAP) и в аналитических панелях (Dashboards). Его результаты можно отобразить с помощью визуализаторов, доступных в этих инструментах.
Неоспоримые возможности и удобства BI-поиска в платформе:
- учет словоформ и синонимов;
- гибкое управление релевантностью;
- формирование ключевых слов для увеличения релевантности поиска;
- возможность мультиязычной индексации\поиска;
- подсветка найденных результатов;
- семантическое формирование поискового запроса к Solr на основании входного запроса пользователя;
- индексация и поиск пользовательских сущностей;
- индексация и поиск объектов репозитория.
Затрагивая вопросы индексации (*) данных, отметим ее следующие преимущества:
- использование контейнера задач для запуска процесса индексации (очень удобная штука);
- возможность частичного обновления индекса;
- настройка параметров индексации через пользовательский интерфейс.
Что касается непосредственно поиска, то здесь в вашем распоряжении:
- фасетный поиск;
- расширение настроек поиска: фильтрация, сортировка, задание формулы для управления релевантностью поиска;
- привнесение семантики в формирование запроса к Solr;
- помощь в генерации файла с синонимами.
Relax. Take it easy!
Давайте рассмотрим пример, раскрывающий все (или почти все) возможности BI-поиска.
Допустим, вам интересно узнать что-нибудь, связанное с нефтью, Россией и 2010 годом. Вводим в поисковую строку, например, запрос «нефть Россия 2010». В результате мы видим, что данная информация содержится в двух источниках данных: «Показатели мирового развития» и «IMF – Перспективы развития мировой экономики».
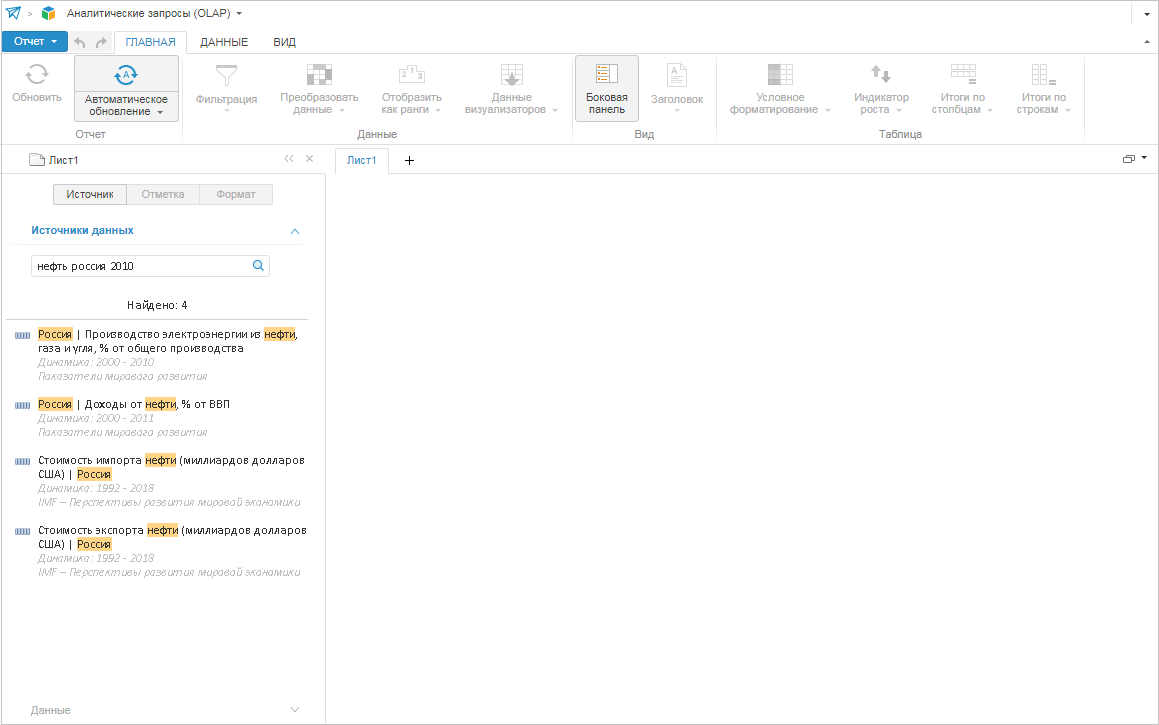
Однако первый источник нас не интересует. Тогда добавим в запрос слово «IMF», и вуаля! В результатах поиска только данные, относящиеся к нужному источнику. Снова выбрав результаты поиска и удобный способ отображения, вы будете готовы к дальнейшему анализу данных.
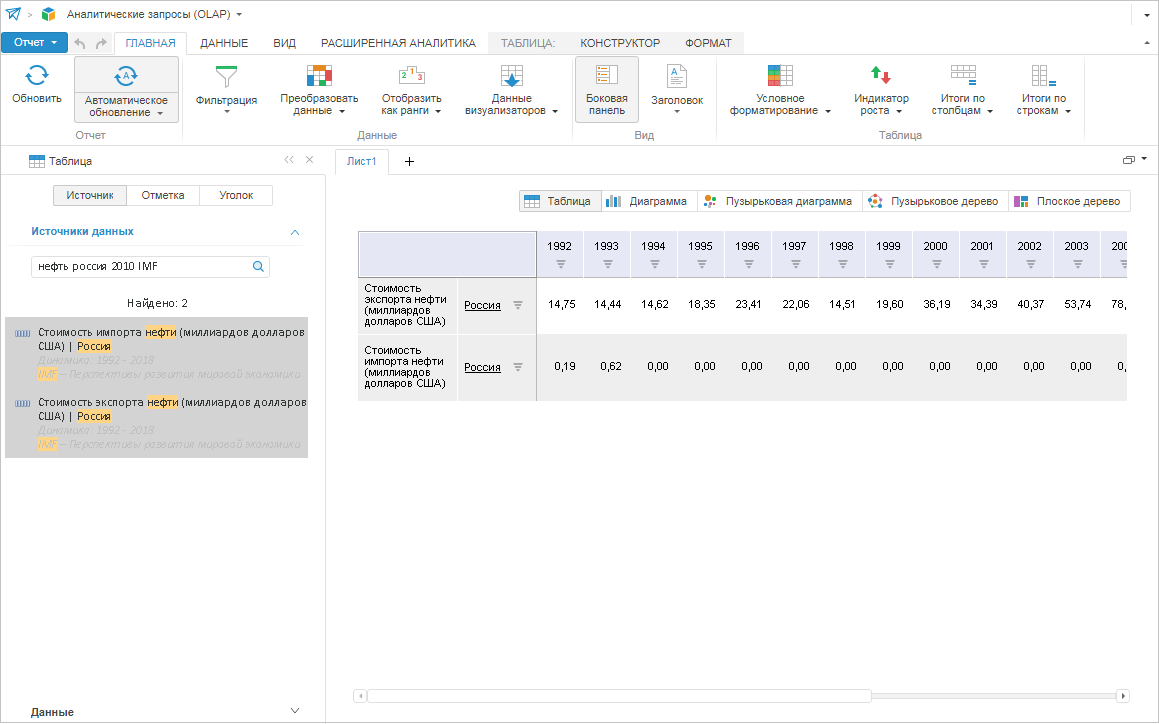
Существует возможность индексации и поиска объектов репозитория: документы, таблицы, отчеты и т.д. Кстати, для документа индексируется его контент. И это хорошо, если вдруг не вспоминается его точное название, но помнится, о чем он. Кроме того, индекс объектов репозитория можно также расширить пользовательскими данными.
Поисковая модель данных для объекта репозитория содержит в себе:
- ключ;
- идентификатор;
- наименование;
- идентификатор класса;
- наименование класса;
- описание;
- дату изменения;
- контент (если объект – документ).
Маленькие радости большой индексации
Не запускать же вручную
По понятным причинам поисковый индекс должен всегда находиться в актуальном состоянии. Изменилось содержимое источника данных или пользовательских данных – должен измениться и индекс.
Чтобы упростить и автоматизировать этот процесс, индексацию можно настроить через контейнер запланированных задач.
В контейнере отвечает за это тип задачи «Обновление поискового индекса», а диалог настройки задачи выглядит так:
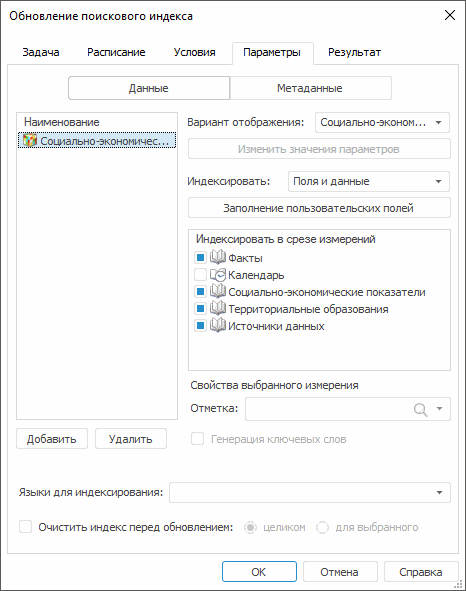
Очень удобно, особенно если данные обновляются ежедневно. И правда, не запускать же каждый день индексацию вручную.
Не писать же все время код
В платформе существует возможность задания настроек для индексации (и немного для поиска) через интерфейс. Действительно, не писать же все время код.
Пример настройки до Solr.
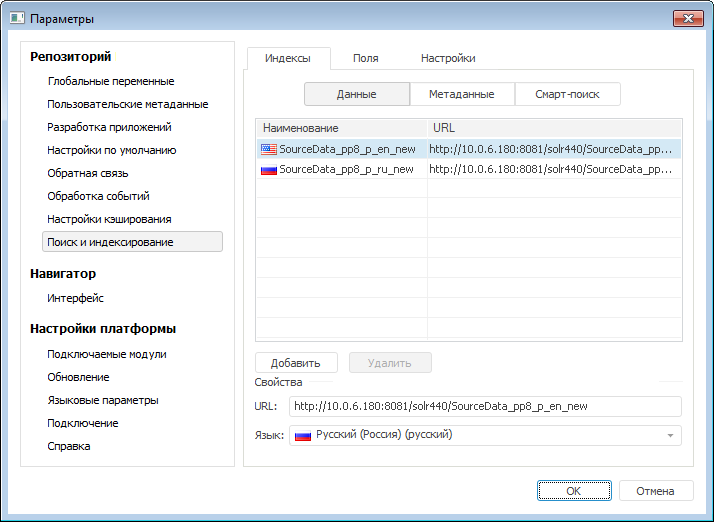
Пример конфигурирования пользовательских полей:
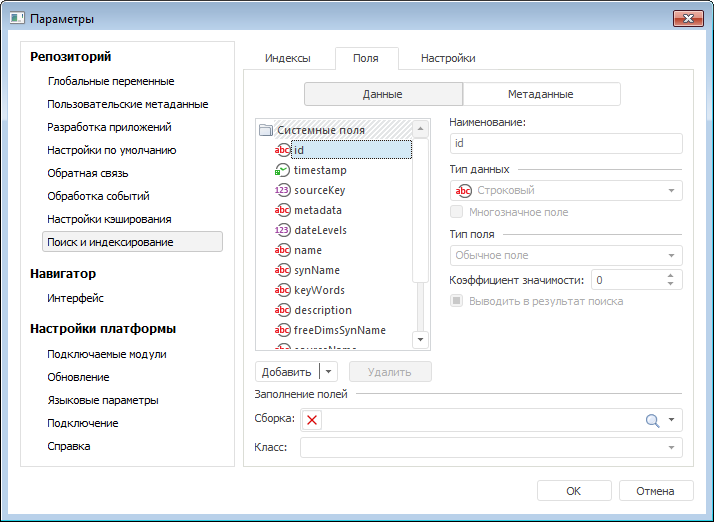
Сами с усами, или «умный» поиск
Давайте попробуем разобраться, зачем в действительности может понадобиться «умный» поиск. Несложно догадаться, что он необходим для улучшения релевантности. Постараемся вникнуть в механизм его работы.
Начнем с теории для понимания. Или, другими словами, для понятий, которыми мы оперируем, работая с BI-поиском.
Свободное измерение – это измерение, по которому производится поиск, но элементы такого измерения не включаются в наименование результата поиска.
Пример: пусть в источнике имеется два измерения «Показатели» и «Территории».
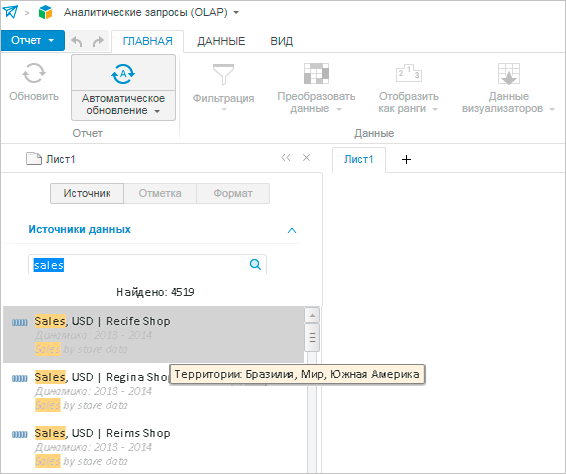
Вариант №1: Если в параметрах индексации измерение «Показатели» указать как свободное, то наименование результата поиска формируется просто: Показатель (т.е. территория не попала в наименование). Однако поиск по территориям осуществляться, конечно, будет, а сам результат поиска будет также содержать список стран, т.е. список элементов свободных измерений.
Пример результата поиска по индексу источников со свободным измерением «Территории»:
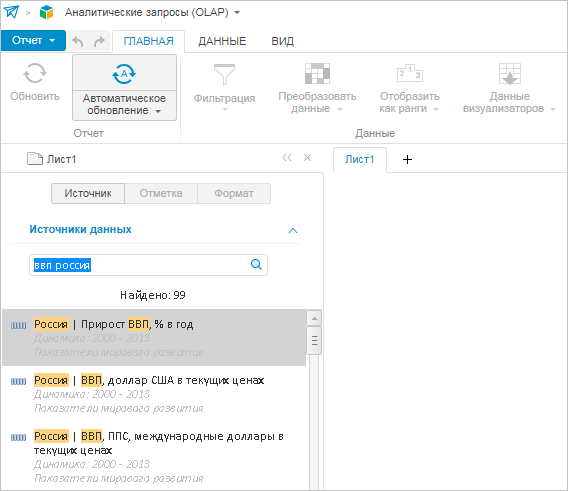
Вариант №2: Если в параметрах индексации не указать ни одного свободного измерения, то наименование результата поиска формируется так: Территория | Показатель.
Пример результата поиска по индексу источников без свободных измерений (страна «Россия» вошла в наименование результата поиска).
Для понимания механизма работы «умного» поиска необходимо также упомянуть о том, как происходит формирование запроса для поиска по документам Solr.
Пусть пользовательский запрос «ВВП России», а поисковый документ (**) состоит из двух полей (***) – name и freeDimensions, тогда в общем случае (без свободных измерений) запрос к Solr формируется так:
name: (ВВП OR России) AND freeDimensions: (ВВП OR России).
Т.е. в каждом поле ищется каждое слово.
(*): Для того чтобы что-то искать, нужно это что-то куда-то положить. В нашем случае «что-то» – это содержимое источников данных, а «куда-то» – это индекс Solr. А процесс перекладывания «что-то» в «куда-то» называется индексацией.
(**): Индексация из (*) занимается тем, что формирует эти самые поисковые документы, среди которых мы ищем и, если что-то нашлось, то это добавляется в результат поиска.
(***): Поисковые документы из (**) состоят из полей (подробнее здесь), которые содержат в себе какую-либо информацию описываемой сущности.
Однако при использовании «умного» поиска и указании хотя бы одного свободного измерения:
• на этапе индексации вместе с основным строится дополнительный индекс, состоящий из элементов свободных измерений;
• на этапе поиска каждое слово из пользовательского запроса проверяется на принадлежность к свободному измерению:
- если слово из свободного измерения, то оно будет искаться только в поле freeDimensions.
- если слово не из свободного измерения, то оно будет искаться только в поле name.
• результирующий запрос к Solr в упрощенном виде выглядит так:
name: (ВВП) AND freeDimensions: (Россия)
Итак, что же нам дает такое формирование запроса?
Во-первых, это обеспечивает более «чистую» релевантность. Действительно, зачем искать «Россию-матушку» в наименованиях, если заранее известно, что ее там нет и не будет.
Во-вторых, это позволяет получить более качественные результаты поиска, поскольку «Россия» не будет искаться в наименовании, где могут содержаться однокоренные слова, например, в словосочетании «российский» рубль.
Все еще формируете файл с синонимами без окончаний вручную?
Тогда мы идем к вам!
Для того чтобы Solr искал по синонимам с учетом падежей слова, необходимо сформировать файл с синонимами, слова в которых – без окончаний.
В каждом языке имеются тысячи и тысячи синонимов. Неужели мы обречем вас на то, чтобы формировать каждое слово-синоним без окончания по правилам Solr еще и в зависимости от используемого языка? Конечно, нет, потому что «Форсайт. Аналитическая платформа» обеспечивает автоматизированное заполнение файла синонимов без окончаний.
Подведем итоги
В платформе имеется возможность индексации и поиска пользовательских сущностей, а также объектов репозитория.
Для осуществления процесса индексации используются такие удобности, как контейнер задач, частичное обновление индекса и настройка параметров индексации через интерфейс.
Существуют разнообразные возможности в использовании непосредственно поиска: фасетный поиск, расширение настроек поиска, автоматизированная генерация файла синонимами и, конечно, повышение релевантности поиска за счет использования «умного» поиска.
Возможности BI-поиска в продукте «Форсайт. Аналитическая платформа» – широки. Поиск осуществляется по всем измерениям источника, будь то измерение показателей, стран или календарное.
Таким образом, обеспечивается возможность уточнения результатов поиска при больших объемах индекса. Результат поиска содержит всю необходимую информацию, а найденные слова при поиске подсвечиваются. Индексация и поиск могут осуществляться на различных языках (русский, английский, французский и т.д.).